Step 3 of 6 in the mech interp curriculum. Assumes you've done steps 0-2.
We replicate the most foundational discovery in transformer interpretability: induction heads (Olsson et al., Anthropic, 2022). These are a specific two-attention-head circuit that lets transformers do in-context pattern-matching - copying patterns from earlier in their input. They're most of how language models learn from things you say earlier in your prompt.
The ONE new idea this step teaches: in real transformers, work is done by circuits - multiple attention heads in different layers cooperating. To understand what a transformer does, you have to find these circuits.
By the end you'll have:
- Trained your first multi-layer transformer (step 2 was just one layer).
- Solved a task that requires in-context pattern matching - predicting the next token in a repeated random sequence.
- Inspected the model's attention patterns and seen the two-head induction circuit cleanly.
What's new in this step
Step 2 introduced the single-layer transformer. Almost everything in that project - attention, embeddings, residual stream, weight decay, training loop - is unchanged here. If any of those words feel rusty, re-skim step 2 first.
The only thing actually new in this project:
- Multiple layers. We go from 1 layer to 2. With more than one layer, attention heads in later layers can read what earlier heads wrote into the residual stream. This is the door that lets circuits exist.
- Composition. When a head in Layer 1 builds its query (or its key, or its value) using information written by a head in Layer 0, we say the Layer 1 head "composes" with the Layer 0 head. Composition is the only way multi-head behaviour happens.
- Attention pattern reading. Once trained, we look at the attention patterns of each head - which positions attended to which - and read off, by eye, what algorithm each head implements. This is the most basic mech-interp move on a transformer.
Everything else (nn.Module, attention maths, training loops, etc.) - you already know.
What is an induction head?
Easiest way to define it is by what it does on a specific input.
Suppose the model has seen the sequence so far:
... the cat sat on the mat ... the cat sat on the ___
When the model has to predict the blank, it would be helpful to notice that "the cat sat on the" has appeared earlier, and that the very next token last time was mat. An induction head does exactly that:
- At the current position, look for an earlier occurrence of the same token (
the). - Find what came right after that earlier
the(which wasmat). - Predict
mat.
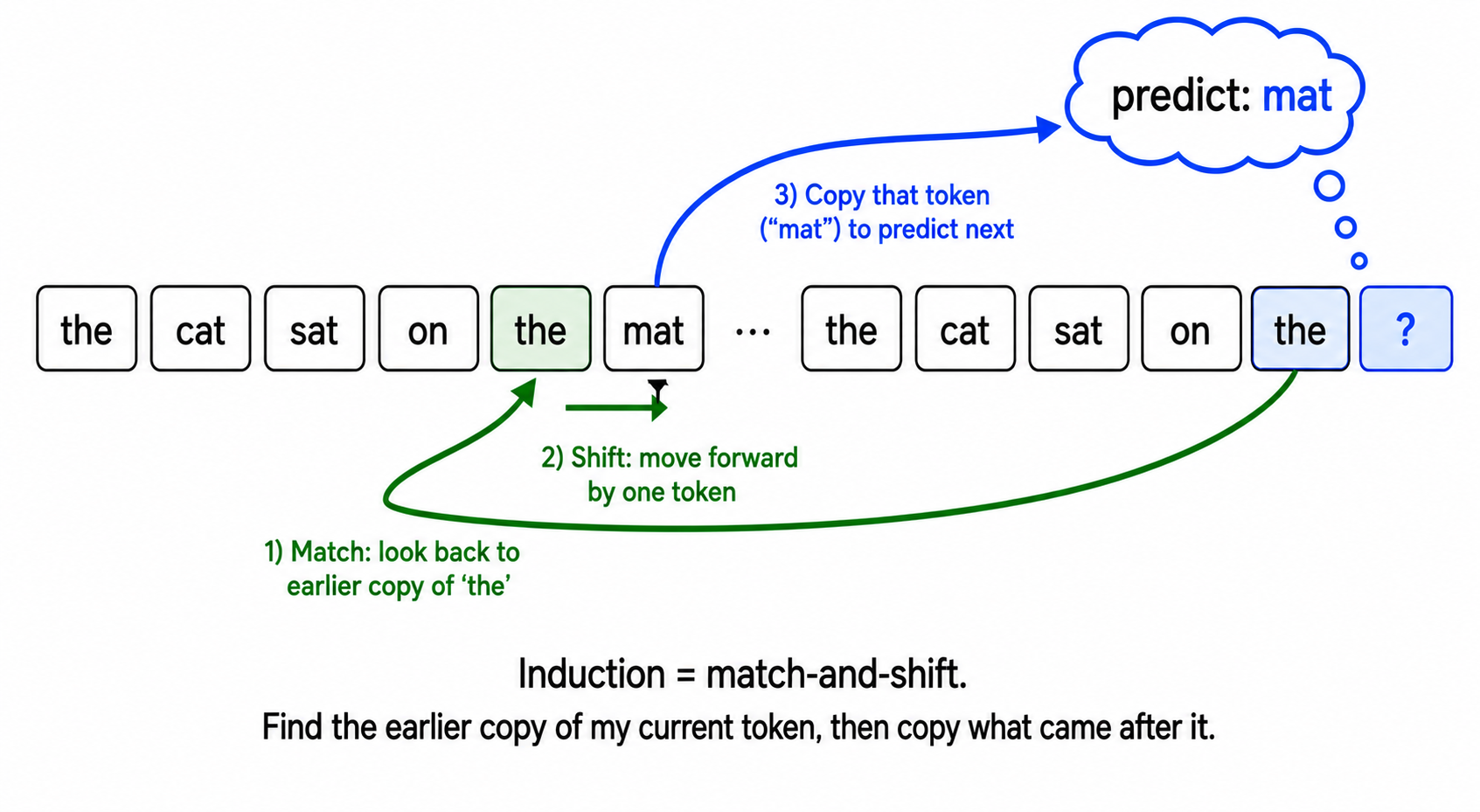
Mechanically, the induction head's attention pattern at the current position is concentrated on the position immediately after the earlier matching token. It copies the value at that position to the residual stream, which the unembedding then reads out as a prediction.
This is the entire trick behind a huge fraction of in-context learning. Tell GPT-4 "translate French to German" and give it examples; under the hood, induction heads are picking up on patterns like "the last time we saw a French word followed by a German word, the German word came after a :, so this time predict a German word."
Olsson et al. 2022 argues induction heads are the single most important discovery in transformer interpretability so far. We're going to find them ourselves.
The experiment in plain English
The task. We design a synthetic task that can only be solved by induction. Each input is a length-50 sequence of integers in {0, ..., 63}:
- The first 25 tokens are random.
- The last 25 tokens are the exact same sequence repeated.
So a sample input might be:
[37, 4, 19, 51, 2, ..., 14, 8, 37, 4, 19, 51, 2, ..., 14, 8]
(random first half) (same sequence repeated)
To predict the next token at position 30 (for example), the model needs to look at position 30-25=5 and read off what comes after. There is no other algorithm that can solve this task - the tokens are random and uncorrelated, so memorising distributions doesn't help. Generalising bigrams/trigrams doesn't help. The model has to learn induction.
The model. A 2-layer attention-only transformer (no MLPs). 4 attention heads per layer. d_model = 64. Total: ~50k parameters. Tiny.
Training. A few thousand steps of AdamW on freshly-sampled batches of random repeated sequences. Loss is cross-entropy on next-token prediction across all positions. We separately track loss on the first half (where it's unsolvable, ~log(64)) vs the second half (where it should drop to near zero).
What we expect. After training:
- Loss on the first half stays at ~
log(64) ≈ 4.16- the model can't predict random tokens it has never seen. - Loss on the second half drops to near zero - the model has learnt induction.
- When we plot the attention patterns of all 8 heads (2 layers × 4 heads each), exactly two of them will have distinctive structure:
- One head in Layer 0 will have a previous-token pattern (sub-diagonal).
- One head in Layer 1 will have an induction pattern (diagonal shifted by one half).
The other 6 heads will look more uniform or noisy. That's normal - not every head specialises, and some are doing supporting work.
The circuit explained
Here's why this two-head combination works. You don't need to follow the maths in detail on a first read - but the picture matters.
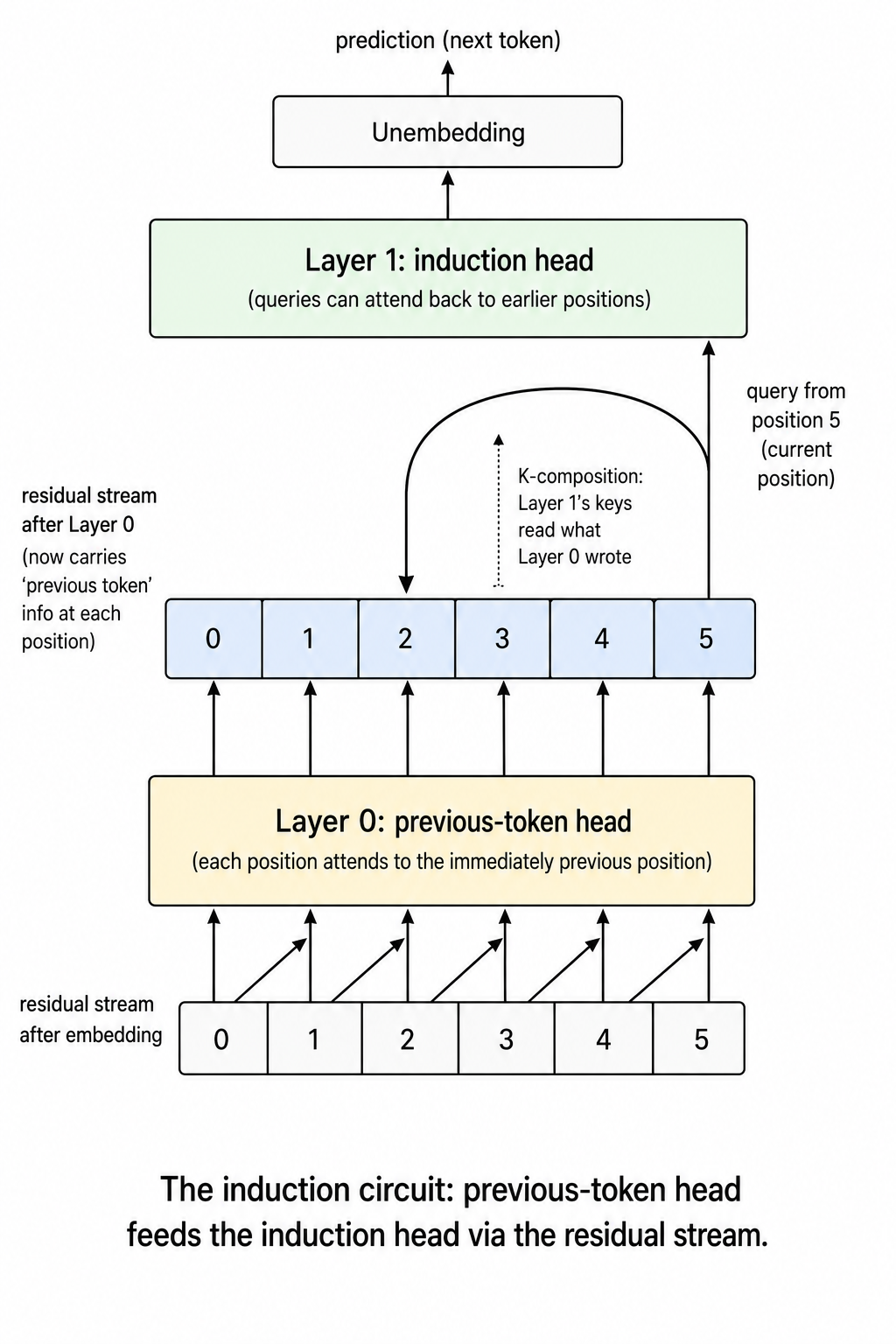
Imagine the model is at position T in the second half of the sequence, holding token X. It wants to predict what comes next. The right answer is "whatever came after X last time X appeared, which was at position T - 25. So I want to predict the token at position T - 24."
The induction head's job is to attend from T directly to T - 24 and copy that token's identity.
The problem: at position T - 24, the residual stream only knows about itself - about the token at position T - 24. There's no way for the induction head to know "this position is one-after-an-X" just by looking at position T - 24's residual stream.
The fix (the previous-token head, Layer 0): this head, at every position p, attends to position p - 1 and copies that earlier token's information into position p's residual stream. So after Layer 0, the residual stream at position T - 24 carries information about both the token at T - 24 and the token at T - 25 (which is X).
The induction head (Layer 1) closing the loop: this head, at position T:
- Builds a query that says "I am looking for a position whose previous token was X."
- Builds a key for each candidate position using the output of the previous-token head. So position
T - 24's key encodes "my previous token was X." (It also encodes other things, but X is in there.) - The query-key match fires when the candidate's previous token equals the destination's current token - exactly the induction condition.
- The value copied back is just the candidate position's actual token identity, which then gets read out as the prediction.
This is K-composition: the induction head builds its keys using the output of the previous-token head. Layer 1's keys read from what Layer 0 wrote into the residual stream.
When you visualise the Layer 1 head's attention pattern in Section 7 of the notebook, you'll see a clean diagonal shifted by 25 positions - that's this whole machine working.
crack open as needed
Glossary - terms added in this step
Just the new ones. For terms from earlier steps see those step pages.
- Attention pattern: the matrix of attention weights for one head, after softmax. Shape
(query_position, key_position). Entry[i, j]is "how much does the token at positionilook at the token at positionj?" Visualising this matrix as a heatmap is the basic interpretability move on a transformer. - Previous-token head: an attention head whose attention pattern is a clean sub-diagonal - every position attends to the position immediately before it. The job is "tell me what was just said." Found in Layer 0 of our trained model.
- Induction head: an attention head that, given the current token
X, attends back to the position right after the last timeXappeared, and copies that next-token's identity forward. The job is "I've seen this before - last time, what came next?" Found in Layer 1. - Circuit: a small, identifiable subgraph of a neural network that implements an interpretable algorithm. The previous-token head + induction head together form the induction circuit.
- Composition (K-composition, Q-composition, V-composition): a head in a later layer reading from the residual stream what an earlier head wrote there. In our case the induction head K-composes with the previous-token head: it builds its keys from information the previous-token head injected.
- In-context learning (ICL): a model's ability to learn a pattern from earlier in its prompt and apply it to later predictions, without any weight updates. Most of ICL in real LLMs is induction heads doing their job.
- Attention-only transformer: a transformer with all the MLP layers removed. We use this here because the induction circuit forms purely from attention, and removing the MLPs makes it visible without clutter.
Run it
The notebook is induction_heads.ipynb.
01Setup
Imports + device + seeds. Standard.
02Hyperparameters
All knobs in one place: vocab size 64, sequence length 50, model dims, training steps.
03Data generation - random repeated sequences
A function make_batch(batch_size) that returns a (batch_size, 50) tensor: random first half + repeated second half. We don't use a fixed dataset; we generate fresh batches on every step.
04The 2-layer attention-only transformer
Almost identical to step 2's model, but:
- We wrap the attention block in a loop over
n_layers = 2. - No MLP.
- We use the same
Attentionclass from step 2 (you've seen it before).
05Training
~3,000 steps of AdamW. We log loss on the first half and on the second half separately so you can see the divergence.
06Loss curves - the wow moment
Two curves on the same plot. First-half loss stays near log(64) ≈ 4.16. Second-half loss drops to near zero. The gap is the model learning induction.
07Find the previous-token head and the induction head
We compute two scores per head:
- Previous-token score: average attention from position
ito positioni-1. High for a clean previous-token head. - Induction score: on a fresh repeated sequence, average attention from position
25 + kto positionk + 1. High for a clean induction head.
We plot a bar chart of these scores across all 8 heads. Exactly one Layer 0 head should top the previous-token score; exactly one Layer 1 head should top the induction score.
08Visualise the attention patterns of all 8 heads
For each head, plot its attention pattern as a heatmap. Look at the two heads identified in Section 7 first. You should see:
- Previous-token head: a clean sub-diagonal stripe (attention from
itoi-1). - Induction head: an off-diagonal stripe shifted by 25 in the bottom-right quadrant.
The other 6 heads are mostly noisy or uniform.