Step 5 of 6 in the mech interp curriculum. Assumes you've done steps 0-4. (You especially need step 1, which set up the problem this step solves.)
We replicate the core idea of Sparse Autoencoders Find Highly Interpretable Features in Language Models (Cunningham, Ewart, Riggs, Huben, Sharkey; 2023) and Towards Monosemanticity (Bricken et al., Anthropic, 2023).
The ONE new idea this step teaches: you can automatically discover the features a model uses, by training a separate "interpreter" model (a sparse autoencoder) on the original model's hidden activations. No hand-crafted prompts, no head-by-head patching - just train an SAE and read the dictionary it learns.
This step closes the loop on the whole curriculum. Step 1 introduced superposition as the central obstacle of mech interp. Step 5 introduces SAEs, the field's current best partial solution.
By the end you'll have:
- Trained a toy model that uses superposition (a slightly bigger version of step 1's setup).
- Trained a sparse autoencoder on the model's hidden activations.
- Verified that the SAE's learnt features recover the original model's ground-truth features - by cosine similarity, not by hand.
Why this step exists
Step 1 named the problem: real models pack features in superposition, so individual neurons stop being interpretable. Steps 2–4 worked around that - finding circuits by hand, verifying them by hand. This step automates the feature-finding part.
The pitch for an SAE in one sentence: train a wider autoencoder on the model's hidden activations, with a sparsity penalty, and the directions it learns will be the model's actual features.
What is a sparse autoencoder?
A sparse autoencoder is a small neural network with three pieces:
input x (d_input dims)
│
▼
┌──────────┐
│ encoder │ W_enc, b_enc → ReLU
└──────────┘
│
▼
hidden h (d_sae dims) ← d_sae > d_input (the dictionary; many more "features" than the input has dimensions)
│
▼
┌──────────┐
│ decoder │ W_dec
└──────────┘
│
▼
output x̂ (d_input dims)
Forward pass:
h = ReLU(W_enc @ x + b_enc)
x̂ = W_dec @ h + b_dec
Loss:
L = ||x - x̂||² (reconstruction - must faithfully decompose the input)
+ λ ||h||₁ (sparsity - penalises the number of features used)
The ReLU on h is essential - it means each feature can be off (h_i = 0) or active to varying degrees (h_i > 0), but never negative. Combined with the L1 penalty, the SAE is pushed toward solutions where most features are off and only a few fire on any given input.
After training, each column of W_dec is one feature direction in the input activation space. The SAE has learnt a dictionary of d_sae directions, and represents each input activation as a sparse, non-negative combination of those directions.
This is what fixes the superposition problem. The original model packs many features into fewer dimensions (project 1). The SAE projects back out into a higher-dimensional space where each feature can have its own dedicated dimension.
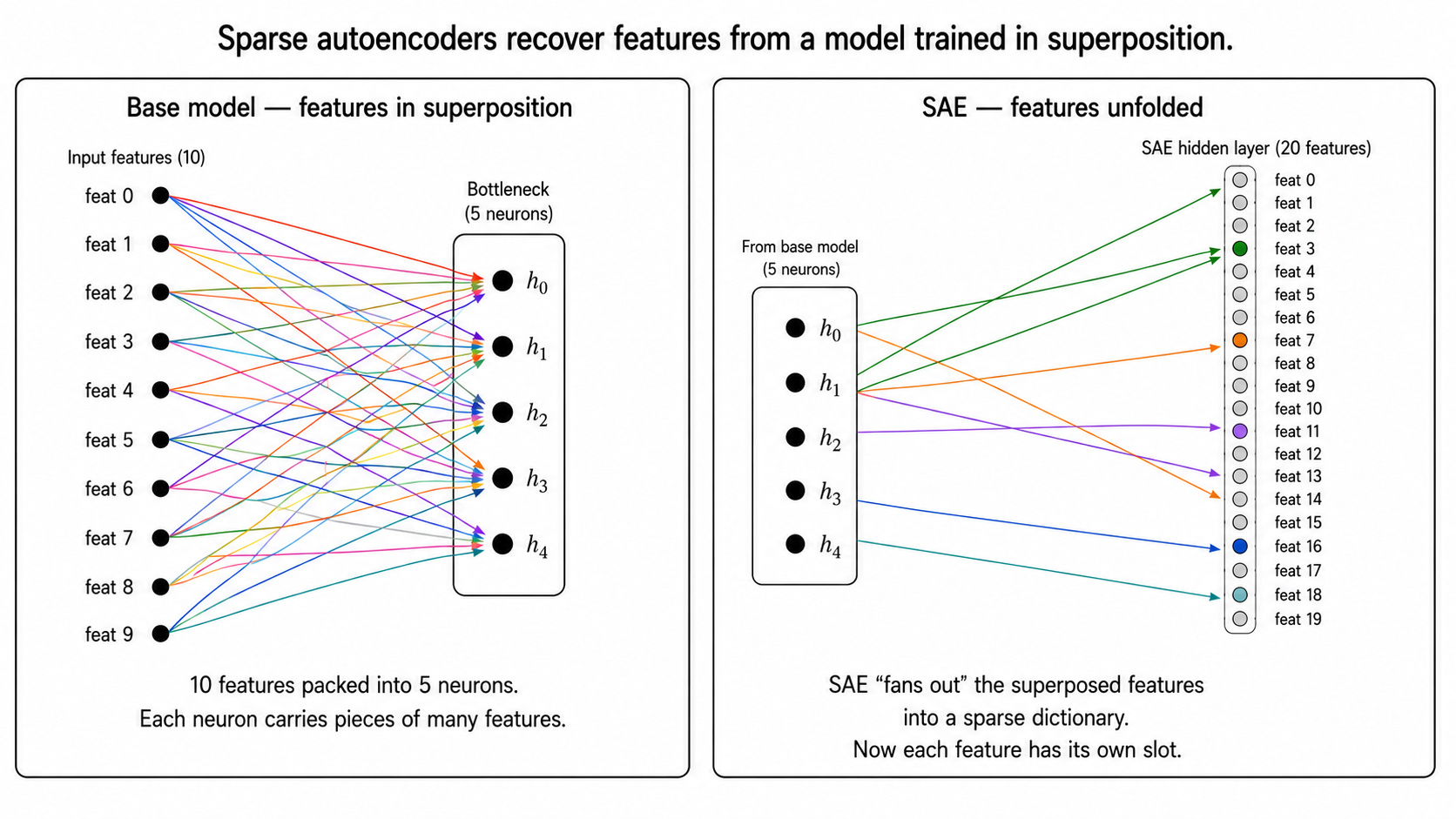
The experiment in plain English
We want to verify, in a setting where we have ground truth, that an SAE actually finds the real features.
The setup: train a project-1-style toy superposition model. Specifically:
n_features = 10(the ground-truth features)n_hidden = 5(the bottleneck dimension)sparsity = 0.9(90% of features off on average)
This model packs 10 features into 5 hidden dimensions. We know the ground-truth feature directions: they're the 10 columns of the model's W matrix.
The SAE: train a sparse autoencoder on the model's hidden activations.
- Input: 5-dim (the model's hidden state)
- SAE width: 20 features (overcomplete by 4×)
- Sparsity: L1 coefficient
λ = 0.001
The test: after the SAE has trained, compute the cosine similarity between each SAE feature direction and each ground-truth feature direction. Build a 20×10 matrix and plot it. If the SAE has recovered the features:
- Each ground-truth feature should be matched by at least one SAE feature with cosine similarity ≈ 1.
- The SAE features not matched to any ground-truth feature are "dead" or redundant - that's normal.
This is the wow moment: the SAE didn't know about the 10 ground-truth features. It only ever saw 5-dim hidden activations from a trained model. With nothing but the L1 penalty as guidance, it recovers the original feature decomposition.
crack open as needed
Glossary - terms added in this step
- Sparse autoencoder (SAE): an autoencoder whose hidden layer is wider than its input, trained with a penalty that forces only a few hidden units to fire on any given input. The "wider hidden than input" part is essential: if the hidden layer is the same size as the input, the obvious solution is the identity function and no features get found.
- Dictionary learning: the general field of "find a sparse representation of data as combinations of basis elements." SAEs are a specific neural-network version. The "dictionary" is the set of basis elements (= the SAE's decoder columns).
- Encoder / decoder: the two halves of an autoencoder. Encoder maps input → hidden (the dictionary coefficients). Decoder maps hidden → output (a reconstruction).
- L1 penalty / L1 loss: a loss term proportional to the sum of absolute values of the hidden activations. Penalises any nonzero activation, so the optimiser prefers solutions that use as few hidden units as possible.
- Reconstruction loss: the standard MSE between the SAE's output and its input. The SAE has to faithfully reproduce the original activation.
- Feature direction (in an SAE): a column of the decoder weight matrix. The SAE represents each input as a sparse positive combination of these directions.
- Monosemantic feature: a feature direction that, by inspection, corresponds to one clean concept. The interpretability goal. Project 1 defined this term; step 5 makes it operational.
- Feature splitting: when a wider SAE breaks one "feature" from a smaller SAE into several finer ones. A phenomenon you'll see in larger setups; we don't focus on it.
- Sparsity coefficient (λ): the weight on the L1 penalty in the SAE's loss. Higher λ → fewer features active per input but worse reconstruction. Picking this is the main SAE-training hyperparameter headache.
Run it
The notebook is sparse_autoencoders.ipynb.
01Setup
Imports, device, seed.
02Train a superposition model (the "base model")
A slightly bigger version of step 1's ToyModel. We train it briefly at high sparsity so it packs 10 features into 5 hidden dimensions via superposition.
03Collect hidden activations from the base model
Sample a big batch of sparse inputs, push them through the model's encoder, get a (n_samples, 5) tensor of hidden activations. This is what the SAE will be trained on.
04The sparse autoencoder
Two nn.Parameters for encoder and decoder weights plus biases. Forward pass is ReLU encoder → linear decoder, as described above. We tie decoder columns to have unit norm (a small trick that prevents the L1 penalty from being "cheated" by shrinking hidden activations and growing decoder weights).
05Train the SAE
AdamW + cosine schedule. We log reconstruction loss and L0 (the average number of active features per input). Healthy L0 is around the number of features the input is a mixture of - for high-sparsity inputs, that's ~1.
06Compare SAE features to ground-truth features
Compute cosine similarity between every pair of (SAE feature direction, ground-truth feature direction). Plot the 20×10 matrix as a heatmap.
07Visualise the matched feature directions
For each ground-truth feature, find its best-matching SAE feature and plot the two directions side by side. They should look nearly identical.