Step 4 of 6 in the mech interp curriculum. Assumes you've done steps 0-3.
We replicate the core finding of Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small (Wang, Variengien, Conmy, Shlegeris, Steinhardt; 2022). It's the canonical worked example of finding a circuit in a real, pre-trained language model.
The TWO new ideas this step teaches (it's the densest project; one extra is unavoidable):
- Activation patching - the standard tool for causally verifying that a part of a model is responsible for a behaviour. Step 3 visualised attention patterns and inferred function; that's correlational. Activation patching gives causal evidence.
- Working with a pre-trained model you didn't build, via TransformerLens. We load GPT-2 small (124M parameters - ~2000× bigger than the model we trained in step 3).
By the end you'll have:
- Loaded GPT-2 small and confirmed it solves indirect-object identification.
- Activation-patched every attention head in the model and produced the canonical "which heads matter" heatmap.
- Identified the name mover heads at the centre of the IOI circuit.
What's new in this step
- Pre-trained models. Steps 0-3 trained models from scratch. From now on, we use ones other people trained. The shift in mindset is "I don't get to choose the data, the architecture, or the seed; I just have weights and I have to figure out what they're doing."
- TransformerLens. A library that wraps any HuggingFace transformer and gives you clean access to every internal tensor. One-line model loading, one-line attention pattern access, one-line hooks for patching activations.
- Activation patching. A controlled experiment on the model's internals: swap a specific activation with one from a different prompt and measure whether the prediction changes. This converts circuit-finding from "the pattern looks suggestive" to "without this component the model fails in a predictable way."
- Logit difference. The standard IOI metric: how much does the model prefer the right answer over the wrong one, in raw logits?
logit(correct) - logit(distractor). We track this throughout.
Everything else (attention, residual stream, circuits, etc.) you already know from steps 1-3.
The IOI task
Take the prompt:
"When John and Mary went to the store, John gave a drink to ___"
A fluent speaker fills in Mary. The reasoning: John is the subject of "gave," he can't be the indirect object too, so the recipient must be the other name introduced earlier - Mary.
GPT-2 small handles this correctly. The interesting question is how. The model has 12 layers and 144 attention heads. Some specific heads, working together, must be implementing "look at the names mentioned earlier, suppress the one that's also the subject of the current verb, predict the other one."
Wang et al. fully reverse-engineered this circuit. The names they gave to the head groups:
- Duplicate token heads - notice that one name appears twice (
John...John). - Previous token heads - communicate "what came before me" along the sequence.
- Induction heads - yes, the same induction heads from step 3; they do supporting work here.
- S-inhibition heads - read the duplicate-token signal and write a "don't attend to S" message into the residual stream.
- Name mover heads - at the final position, read the inhibition message and the list of candidate names, attend to the non-subject name (the IO), and copy it to the output.
This is a 5-component circuit with about 15 specific heads. We won't replicate all of it - only the cleanest, most striking part: finding the name mover heads via activation patching.
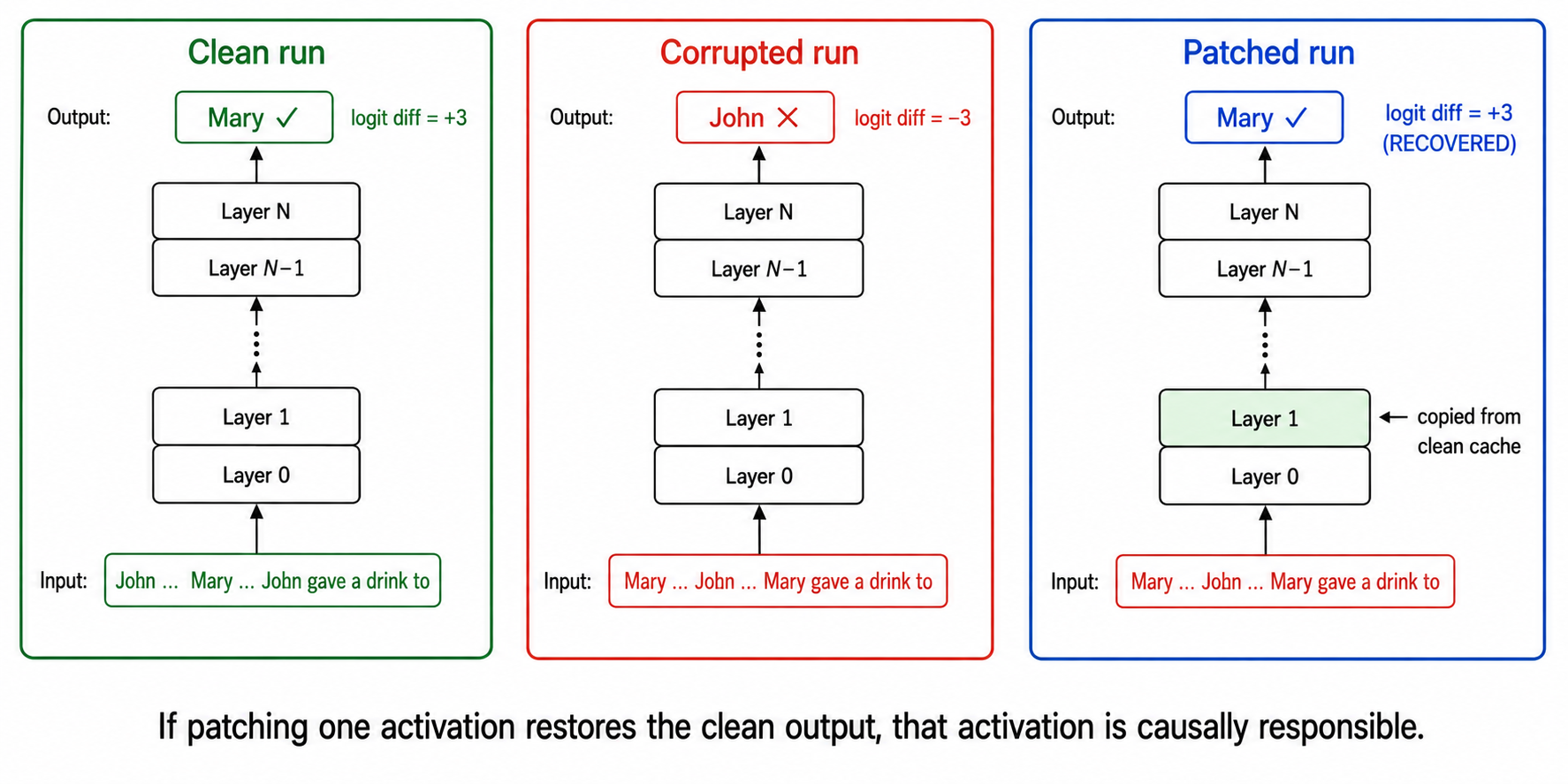
What is activation patching?
Suppose you've found some heads whose attention patterns look like they might be relevant. Are they actually doing the work? Visualisation alone can't tell you - a head might look meaningful but be downstream-ablatable with no effect.
The standard test:
- Clean run: feed the model the original prompt. Cache every activation. Record the logit diff (positive - model gets it right).
- Corrupted run: feed the model a near-identical prompt where the right answer is now the wrong one. E.g. swap the names:
"When Mary and John went to the store, Mary gave a drink to ___"(correct answer is nowJohn, notMary). Logit diff on the original labels (logit(Mary) − logit(John)) is now strongly negative. - Patched run: re-run the corrupted prompt, but at one specific point in the model, replace that activation with its clean-run value. Then continue the forward pass. Measure the new logit diff.
If the patched activation is irrelevant: logit diff stays bad (corrupted-like). The activation didn't matter.
If the patched activation is the thing carrying the IO information: logit diff jumps back toward the clean value. The activation matters causally.
By repeating step 3 for every (layer, head) pair, you get a heatmap of causal importance. The bright cells are your circuit.
This is the tool for converting "this head's pattern looks right" into "this head is causally necessary." Wang et al. introduced it in this form; it's now the bread and butter of mech interp on real models.
The experiment in plain English
The model. GPT-2 small (12 layers, 12 heads each, d_model=768). Loaded pre-trained via TransformerLens. We do not touch the weights.
The prompts. We use a small batch of IOI templates with different name pairs (John/Mary, James/Tom, …) for statistical robustness. For each, we construct:
- Clean:
"When John and Mary went to the store, John gave a drink to"→ expected answer" Mary". - Corrupted (name-swap):
"When Mary and John went to the store, Mary gave a drink to"→ expected answer is now" John"(because Mary is now the subject and John is the indirect object).
We use name-swap corruption rather than the ABC variant from the original paper. ABC has a slightly cleaner causal interpretation but requires a third name that tokenises to one GPT-2 token. Name-swap guarantees identical token lengths automatically and gives a larger logit-diff swing (clean ~ +3 vs corrupt ~ −3 instead of vs ~ 0), which makes the patching results more visually clear. The trade-off is that name-swap corrupts multiple signals at once, so the recovery numbers should be interpreted as "this head transmits the IO identity" rather than the more nuanced statements the paper makes.
The metric. logit_diff = logit(IO) - logit(S), averaged over the batch, using the clean labels throughout.
- Clean logit diff: ~3-4 (model strongly prefers IO).
- Corrupted logit diff: ~−3 (model now prefers S, because S is the IO of the swapped sentence).
The patching sweep. For each of GPT-2 small's 144 attention heads (12 layers × 12 heads), we patch the head's output (z) at the final token position from the clean run into the corrupted run. We measure the new logit diff and express it as a fraction of recovery:
recovery = (patched_diff - corrupted_diff) / (clean_diff - corrupted_diff)
0% = patching had no effect. 100% = patching fully restored the clean prediction.
The expected result. A 12×12 heatmap of recovery percentages. Most cells will be near zero. A small number of cells in the middle-to-late layers will light up strongly - these are the name mover heads (commonly L9H9, L9H6, L10H0, L10H10 in GPT-2 small).
crack open as needed
Glossary - terms added in this step
- Pre-trained model: a model someone else trained and released. We load it, freeze its weights, and study it.
- TransformerLens (TL): Python library for mech interp on HuggingFace transformers. Main class:
HookedTransformer. Wraps a model and exposes every internal activation by name. - Hook: a Python callback registered on a specific activation. When the model runs forward, the hook can read or modify that activation. The mechanism behind patching.
- Cache: a dictionary of all activations from a forward pass, keyed by name.
model.run_with_cache(tokens)returns(logits, cache). - Activation patching (also called interchange intervention or causal mediation): on a "corrupted" run, replace one activation with the value it had on a "clean" run. Measure how much the model's output is restored. The larger the restoration, the more causally important that activation is.
- Clean vs corrupted prompt: a matched pair. The clean prompt is the one where the model gets the right answer. The corrupted prompt is a small perturbation that breaks the right answer (e.g. by swapping the names). Patching activations from clean → corrupted and watching the prediction recover is the actual experiment.
- Logit difference (logit diff):
logit(correct_token) - logit(distractor_token). The standard IOI metric. Positive = model prefers the right answer. - IO (Indirect Object): the correct name to predict in the IOI task. In
"John gave a drink to ___"(after John and Mary were introduced), the IO isMary. - S (Subject): the wrong name - the one the model has to suppress. In the example above,
John. - Name mover head: an attention head that, at the final position, attends to the IO token and copies it to the output. The most causally important heads in the IOI circuit. In GPT-2 small, these are typically
L9H9,L9H6,L10H0. - S-inhibition head: an upstream head that inhibits attention to the subject S. Without these, the name movers would copy S instead of IO. These typically sit a few layers earlier.
Run it
The notebook is ioi_circuit.ipynb.
01Setup
Pip-installs TransformerLens (~30 s). Imports.
02Load GPT-2 small
One line: model = HookedTransformer.from_pretrained("gpt2"). Downloads weights (~500 MB) the first time; cached after.
03Build the IOI prompts
8 templates with different name pairs. For each we build a clean prompt and a name-swapped corrupt prompt. We assert the names tokenise to single tokens and that clean and corrupt prompts have identical token lengths.
04Confirm GPT-2 small solves IOI on clean prompts
Run the model on the clean prompts and check that the top predicted next-token is IO with high probability. Compute clean and corrupted logit diffs.
05Setting up activation patching
Define a hook function that replaces a head's z output (at the final position) with the cached clean value. Define a function patch_head(layer, head) that runs the corrupted prompts through the model with this hook attached and returns the resulting logit diff.
06Run the patching sweep over all 144 heads
Loop over all 144 heads. Computes recovery for each. Takes.
07The heatmap - which heads carry the IO information?
A 12×12 grid showing recovery percentage per head. The name movers should stand out clearly.
08Inspect the name movers' attention patterns
For each head with high recovery, plot its attention pattern on a clean prompt. You should see attention from the final token to the IO position - confirming the "it's looking at the right name" story.
Look at the bars. For the name mover heads, the tallest bar should be over the IO name token (e.g. Mary in our first prompt). That's the head doing exactly what its name suggests: at the final position, it attends to the indirect object name and copies it forward.